Генератор QR кодов
Введите содержимое QR кода и нажмите Генерировать
Нажмите на полученный QR код чтобы скачать
Как работает QR код
1. Чтобы определить, что перед сканером находится именно QR-код, ему нужно за что-то зацепиться. Для этого существуют маркеры позиционирования — три больших одинаковых квадрата по краям каждого кода. Если посмотреть на каждый такой квадрат, то он содержит 3 квадрата: черный большой по краю, черный маленький посередине и белый между ними. Эти квадраты позволяют поделить маркер позиционирования на 5 блоков (по сути вертикальных линий). Две из них по краям черные, две, такой же толщины, содержат белые и черные элементы и самый широкий, по центру, тоже состоит как из белого, так и черного цветов. Соотношение площадей этих блоков и составляет 1:1:3:1:1. Такое уникальное соотношение позволяет быстро определить наличие QR-кода на изображении и его ориентацию, вне зависимости от того, как код повернут относительно сканера.
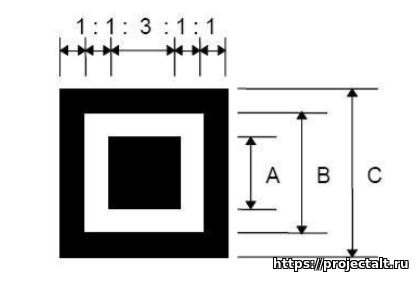
(A,B,C — это 3 квадрата, из которых состоит маркер позиционирования. Блоки, связанные соотношением 1:1:3:1:1, показаны сверху)
(картинки показывают, что вне зависимости от ориентации код будет считан)

2. При помощи этих трех маркеров код может быть определен в идеальных условиях — например, когда вы считываете его с экрана. Но очень часто QR-коды можно увидеть на смятых афишах, ЖД-билетах и даже на стенах домов. Как быть в этом случае? Для этого нужен маркер выравнивания. Можно сказать, он действует как ориентир, позволяющий легче структурировать информацию. Своего рода маяк для сканера. И чем больше информации хранит код, тем больше шаблонов выравнивания он требует и тем большего размера они должны быть. Это тоже достаточно логично: чем сложнее рельеф побережья и чем туманнее погода, тем более мощным должен быть маяк для корабля.

3. Также неподалеку от маркеров позиционирования находятся полосы синхронизации: по чередованию черных/белых точек внутри этих линий сканер определяет размер данных (квадратиков), хранящихся в QR-коде.

4. Маркер версии определяет, к какой из более чем 40 версий принадлежит QR-код. Каждая версия имеет особенности в конфигурации и количестве точек (модулей) составляющих QR-код. Версия 1 содержит 21×21 модулей, версия 40 — 177×177.С увеличением версии меняется только количество информации, которое можно закодировать в QR-коде. Смартфоны обычно способны считывать версии с первой по четвертую, дальше точки становятся для них слишком мелкими.

5. Далее идет информация о формате. В этих ячейках продублирована некоторая системная информация, что увеличивает устойчивость кода к повреждениями, также тут содержится информция о том, солько информации конкретно этот код может потерять, пока она не станет критической для считывания.

6. От окружающих объектов код отделяет тихая зона. Белые рамки вокруг кода позволяют сканеру отличить код от всего, что его окружает. Чтобы сканер случайно не добавил в QR-код муху, сидящую на листке бумаги.

В зоне с информацией квадратов всегда больше, чем нужно, чтобы закодировать наши конкретные данные. Зачем это нужно? Чтобы QR-код был все еще читаем даже при повреждении. Это и называется уровнем коррекции. Их бывает 4: L, M, Q и H. Для самого маленького уровня L допустимо всего 7% повреждений, зато в него можно поместить больше данных. Для самого большого H даже потеря 30% информации не скажется на считывании, но из-за этого придется пожертвовать размером кодируемой информации.
Так, в QR код третьей версии с уровнем коррекции L можно поместить до 53 байт данных, а в аналогичный с уровнем коррекции H — максимум 24.
QR-код поддерживает несколько способов кодирования данных, в зависимости от того, какие символы используются: цифровое, буквенно-цифровое и кандзи (японские иероглифы). Эти способы различаются преимущественно количеством информации, которая требуется на кодирование определенного количества символов. Так, при кодировании цифр нам понадобится 10 бит на 3 символа, а для кодирования букв и символов — 11 бит на 2 символа.
Чтобы закодировать фразу, нам нужно разделить каждое слово на группы по 2 буквы, затем присвоить им номера и перекодировать в 11-битный двоичный код (то есть таким образом, чтобы каждые 2 буквы состояли из последовательности из 11 нулей и ед иниц. Если в слове нечетное количество букв, то последняя буква будет закодирована 6-битным кодом, то есть будет состоять из 6 нулей и единиц). Например, возьмем слово HELLO. После разбивания на слоги это будет HE LL O. В 11-битном двоичном коде это будет выглядеть как 01100001011 01111000110 011000. А если написать все вместе, то 0110000101101111000110011000.
Далее, после выбора уровня коррекции и версии и после добавления всех служебных полей, о которых мы говорили ранее, ( нам следует перевести информацию, которая у нас содержится в битах, в байты, для этого нужно сделать число цифр в коде кратным восьми. Для этого нужно прибавить к последовательности нужное количество нулей. ) В нашей последовательности HELLO 28 цифр. Добавляем 4 нуля и готово. В итоге у нас получается количество байт, которое нужно распределить по количеству блоков, что делает компьютер с учетом всех служебных блоков.